The ZenHire soft skills assessment API grades communication, clarity, and behavioral signals straight from a candidate's spoken answers, returning role-benchmarked 0-100 dimensional scores as JSON from one REST call, so a support or high-volume customer-facing floor hires on how people actually talk to customers.
{
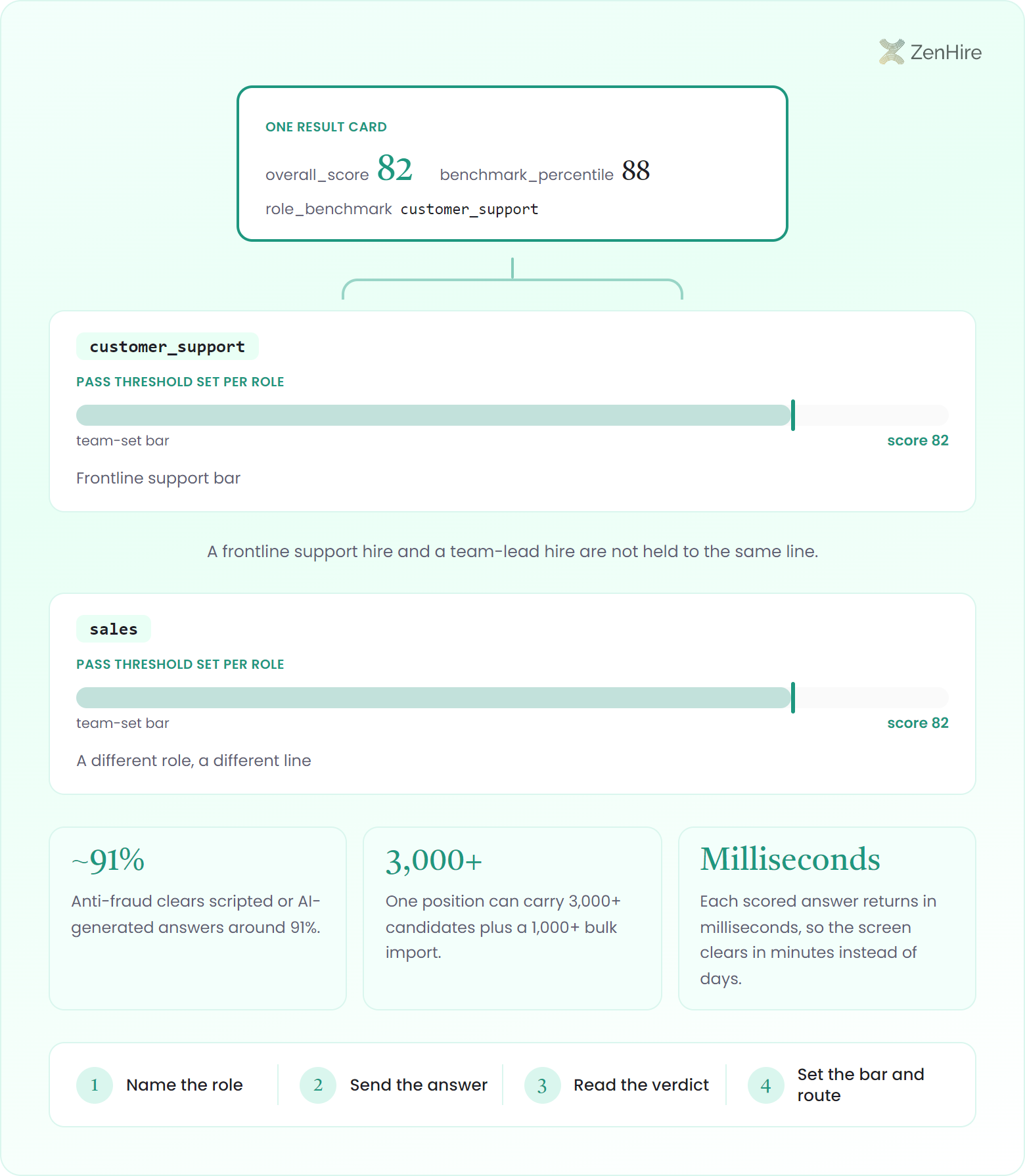
"role_benchmark": "customer_support",
"overall_score": 82,
"dimensions": {
"communication": 85,
"clarity": 80,
"composure": 79,
"empathy_signal": 77
},
"benchmark_percentile": 88,
"fraud_signals": { "reading_detected": false }
}It grades the spoken behaviors that decide a customer call: how clearly someone explains, how they hold composure, and whether their tone reads as helpful. Each returns a 0-100 number alongside an overall verdict.
Where an answer is too short or off-topic to judge a dimension, the API returns a low-confidence flag on that axis rather than a guessed number, so a one-line reply never inflates an empathy score, and when only some dimensions can be scored, credits are charged proportionally, never for a failed run. Behavioral scores tell you how a candidate handles a customer; if you also need to know whether they can be understood in the language of the call, pair this endpoint with the speech analysis api, which layers Vocabulary, Fluency, and Accent scores on the same clip, each 0-100 and each pinned to a [CEFR band from A1 to C2](/assessments/english-proficiency), in 16 languages.
On ZenHire's own benchmarks, language and communication analysis aligns 90-96% with the averaged judgment of five PhD linguists, while untrained human recruiters reach only 68-75%, so the API reads spoken soft skills more consistently than the gut-feel phone screen it replaces.
| Dimension | What it captures |
|---|---|
| communication | 0-100 score for structuring and delivering a clear spoken answer |
| clarity | 0-100 score for how easily a listener follows the response |
| composure | 0-100 score for steadiness and pace under an open-ended prompt |
| empathy_signal | 0-100 read on warmth and helpfulness in tone and wording |
| overall_score | Weighted roll-up of the behavioral dimensions |
| fraud_signals | Per-call reading and multiple-speaker flags on the same audio |

It listens to the acoustic and lexical signal in a recorded answer, pace, pause pattern, word choice, and structure, and maps those patterns to behavioral dimensions, so the verdict reflects spoken delivery rather than a checkbox quiz.
Some teams assume a behavioral assessment api built on speech is a black box that just rewards confident talkers. It is not: scores come from a glass-box, feature-engineered model with sensitive attributes excluded, and every dimension ships with the evidence behind it, so a recruiter can see why a candidate landed where they did and overrule it. The same engine powers the ai interview api, so soft-skill scoring and interview scoring read one shared signal.
You name the role on the request, and the call grades the answer against the behavioral bar for that role plus a percentile against a comparison group, so a frontline support hire and a team-lead hire are not held to the same line.
Each call also runs ZenHire's integrity checks, and built-in anti-fraud detection of scripted or AI-generated answers clears around 91%, so a polished reading does not pass as genuine composure when a bpo floor scores at volume.
One position can carry 3,000+ candidates plus a 1,000+ bulk import, and each scored answer returns in milliseconds, so a high-volume customer-facing screen clears in minutes instead of the days a manual phone-screen backlog takes. Platform defaults allow 500 requests per minute per client, and bursts past the concurrent-run limit queue cleanly with a 202 rather than erroring.
1. Name the role
Pass a role benchmark such as customer_support or sales on the POST to /v1/soft-skills-score.
2. Send the answer
Upload the candidate's recorded response, async or from a live call, as video or audio (MP3, WAV, OGG, FLAC, M4A, AIFF).
3. Read the verdict
Parse the 0-100 dimensions, the role-weighted overall score, and the benchmark percentile.
4. Set the bar and route
Define your pass threshold per role, then auto-shortlist customer-facing applicants at scale.
A soft skills assessment api is a REST endpoint that scores behavioral skills like communication, clarity, and composure from a candidate's spoken answers and returns 0-100 dimensional scores as JSON. ZenHire reads those signals off a single async response of about 4 minutes and grades them against the role you name, so a customer-facing screen collapses into one API request instead of a scheduled listen-through.
A behavioral assessment api measures what a candidate actually does in a spoken answer rather than what they claim on a self-report quiz, the kind you would find in a psychometric test library. ZenHire reads communication, composure, and tone from the recording itself, so a candidate cannot game it by picking the answer they think a recruiter wants, and every score ships with the evidence behind it.
The communication scoring api does not penalize non-native or accented speech. It scores whether a candidate communicates clearly and is understood, not where they grew up, and sensitive attributes like race, gender, and age are architecturally excluded from the inputs and the model that produce each score.
The soft skills assessment API handles high-volume customer-facing hiring through one REST endpoint that grades thousands of recorded answers per role before a human listens to a clip. Each call returns in milliseconds with role-benchmarked scores, so a BPO or retail floor clears a screening backlog in minutes instead of days.
You add the soft skills assessment API by signing up for an API key and sandbox, POSTing a recorded answer with a role benchmark to one endpoint, and reading the JSON scores back, with no model training required. Most teams calibrate thresholds and go live within one to two weeks, and usage is priced per call with no per-seat fees.
Free for Soft skills assessment API spec
A one-page reference for the /v1/soft-skills-score endpoint: every behavioral dimension, the JSON response shape, role-benchmark and threshold options, the fraud_signals fields, and how the glass-box scores stay explainable for review.
Score communication and behavioral soft skills from one recording, benchmarked to the role, at volume.