The ZenHire candidate scoring API returns a single explainable 0-100 fit score per applicant, folding CV match, assessment results, and interview signals into one ranked, percentile-placed list, with each signal's contribution shown, from one REST call.
{
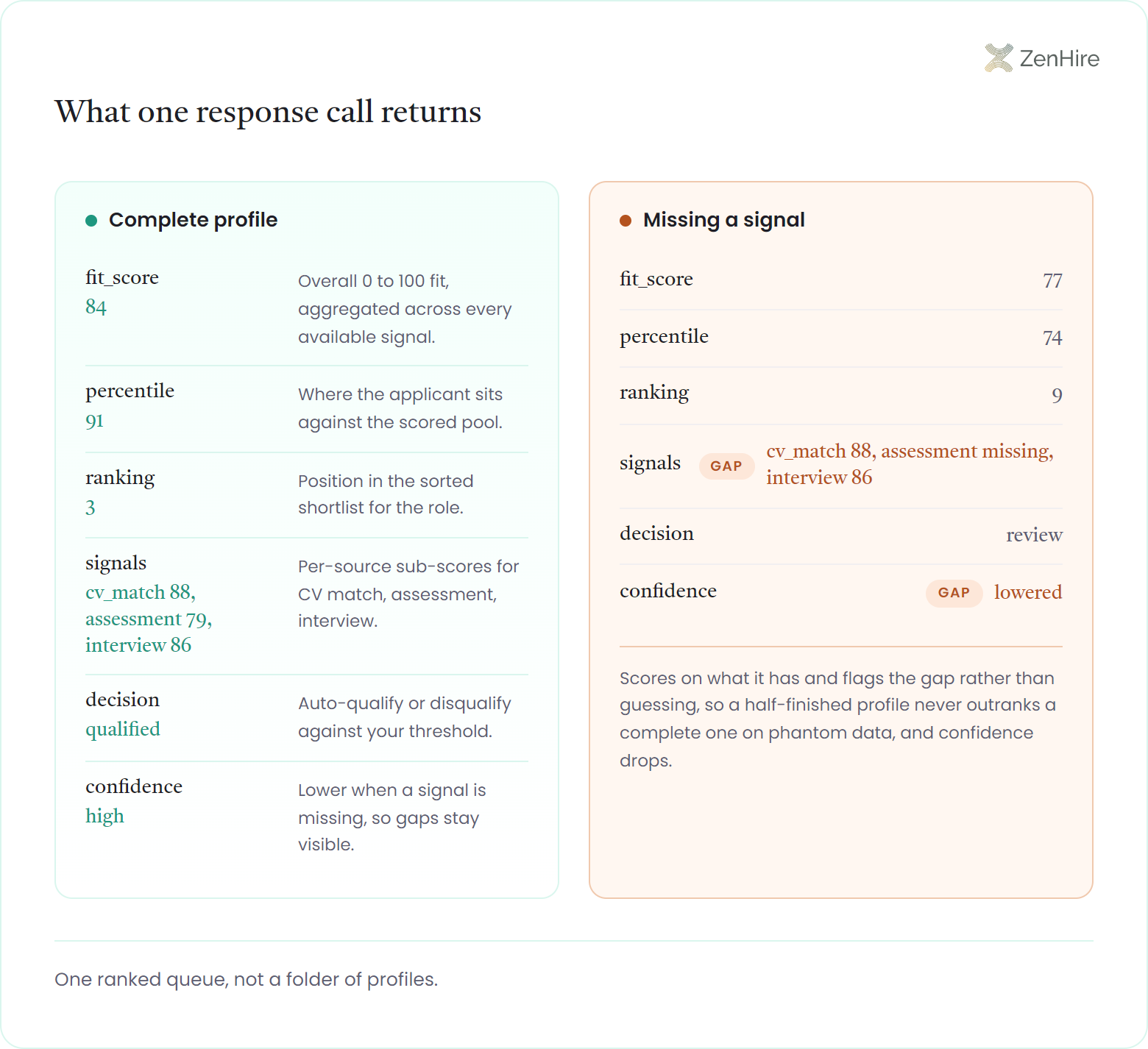
"fit_score": 84,
"percentile": 91,
"ranking": 3,
"signals": {
"cv_match": 88,
"assessment": 79,
"interview": 86
},
"decision": "qualified"
}Each applicant earns one 0-100 number that weighs how well their evidence meets a role, then the pool sorts by it, top of the list first, with a percentile to show how far ahead. You read a ranked queue, not a folder of profiles.
When an applicant is missing a signal, whether no assessment taken yet or no interview recorded, the API scores on what it has and flags the gap rather than guessing, so a half-finished profile never outranks a complete one on phantom data. Billing follows the same honesty: a run that fails is never charged, and the platform checks your credit balance before processing begins rather than partway through. It is engineered to rank pools of 3,000+ candidates per role without slowing down, which is why the applicant ranking api for high-volume hiring suits campaign-scale openings and any high-volume hiring program that screens at scale.
A single high-volume role can pull 2,000 to 5,000 applications, and manual screening can't keep up. The candidate scoring API ranks the whole pool in milliseconds per call, so a recruiter opens the strongest profiles first instead of reading the avalanche top to bottom. Default platform limits hold 500 requests per minute per client, and anything beyond 8 simultaneous processing runs queues cleanly with a 202 instead of an error, so campaign-scale bursts never drop applicants.
| Field | What it carries |
|---|---|
| fit_score | Overall 0-100 fit, aggregated across every available signal |
| percentile | Where the applicant sits against the scored pool |
| ranking | Position in the sorted shortlist for the role |
| signals | Per-source sub-scores: CV match, assessment, interview |
| decision | Auto-qualify or disqualify against your threshold |
| confidence | Lower when a signal is missing, so gaps stay visible |
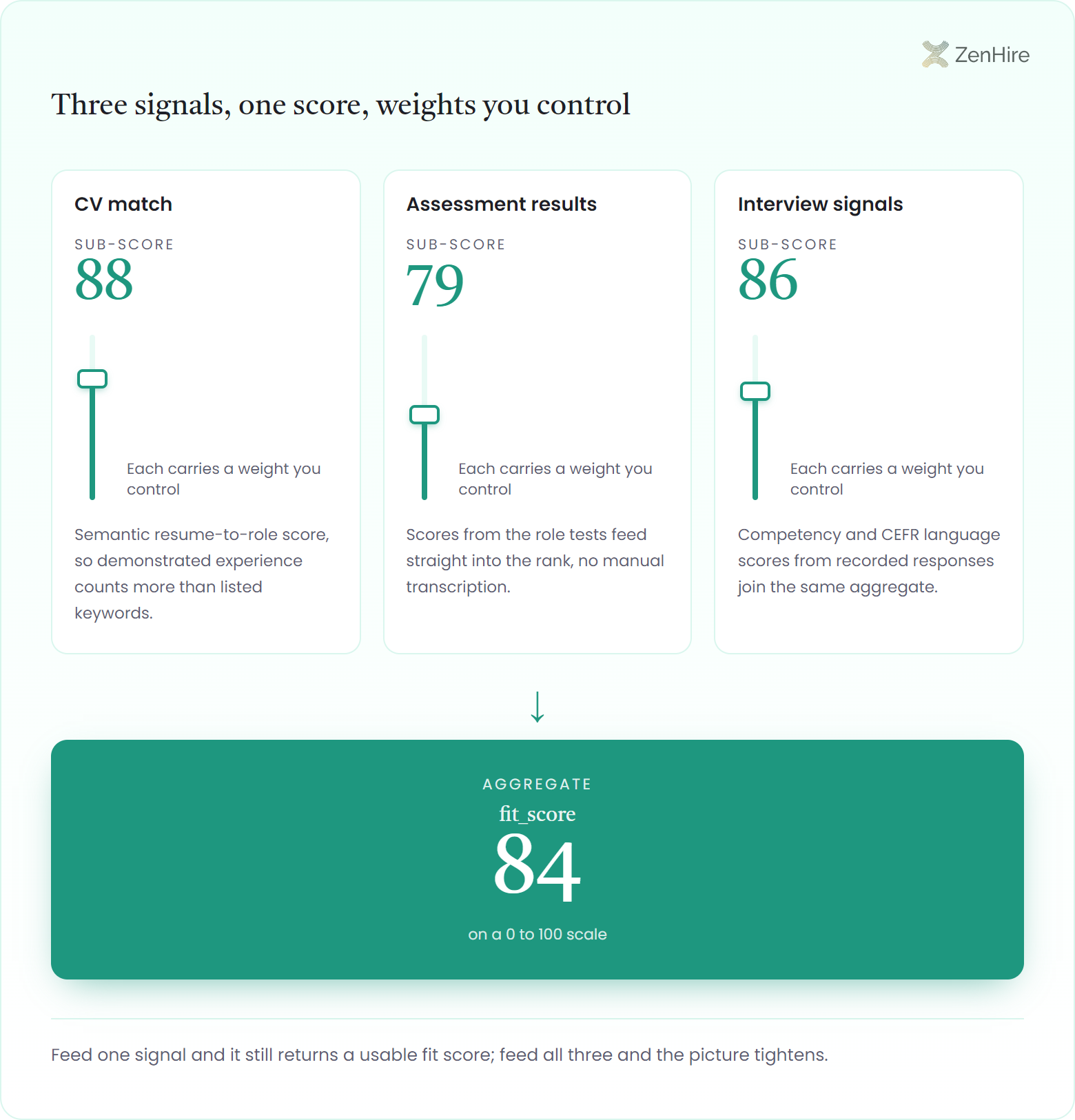
Three inputs combine: how closely a resume matches the job, how an applicant performed on role assessments, and what their interview responses scored on competency and language. Each carries a weight you control.
Feed it one signal and it still returns a usable fit score from that source alone; feed it all three and the picture tightens. A semantic cv-to-role match score anchors most rankings: every requirement behind it carries an importance weight from 1 to 5, spanning hard skills, soft skills, qualifications, industries, and languages, and the match resolves in a typical 1 to 3 minutes end to end, delivered by polling or signed webhooks. Where a role weights spoken English heavily you can lift the interview competency and language signal without touching the others.
Every score arrives with the breakdown that produced it: each signal's value and how much it moved the total. A recruiter reads the why, not just the number, and overrides when judgment disagrees.
Some teams assume a single aggregate score hides its workings the way a black-box model would. It does not. The architecture is glass-box and deterministic: the same inputs return the same score, the contribution of each signal is published, and sensitive attributes are excluded from inputs and models, so each decision stays auditable under a right to explanation. The same discipline runs through the plumbing: retries are safe because an idempotency key holds for 24 hours and returns the original run instead of a duplicate score, while result webhooks are HTTPS-only, carry Stripe-style HMAC-SHA256 signatures, and exclude PII fields from every payload. That same evidence-first scoring drives the explainable cv-to-job match engine, and the bias-mitigated scoring approach keeps demographic factors out of the ranking entirely.
The whole case for a single fit score rests on which signals you feed it. A resume read in isolation forecasts on-the-job performance at roughly r = 0.14 — barely better than chance for ranking. Stack a semantic CV match on top of role assessments and a structured interview and that aggregate climbs past 0.6, so the number this API returns carries more than four times the predictive weight of the CV screen it replaces. Weighting those validated signals into one auditable score is exactly what the endpoint does.
1. Read the total
Start with the 0-100 fit score and the applicant's percentile against the pool.
2. Open the signals
Inspect the per-source sub-scores: CV match, assessment, interview.
3. See each share
Check how much each signal contributed, so a surprising rank explains itself.
4. Override on judgment
A human keeps the final call; the audit trail records the change.
The candidate scoring API is a REST endpoint that returns one explainable 0-100 fit score per applicant, aggregating CV match, assessment results, and interview signals into a single ranked, percentile-placed list. It auto-qualifies or disqualifies against thresholds you set, and ships the per-signal breakdown behind every score.
The applicant ranking API orders a pool by each applicant's 0-100 fit score, top first, and attaches a percentile so you see how far ahead a leader sits. Calls run in milliseconds each, so a full pool sorts before a recruiter opens the first profile, and you set the threshold that splits qualified from not.
The candidate fit score API bases its number on up to three weighted signals: a semantic CV-to-job match, role assessment results, and interview competency and soft skills scores. You control the weights, and each signal's contribution ships with the result, so the score is auditable rather than opaque.
The candidate scoring API aligns with human screeners more than 93% of the time and excludes sensitive attributes from its inputs and models by design to reduce bias in hiring. Because it scores demonstrated evidence and keeps every decision explainable, it tends to advance capable applicants that rigid filters reject for the wrong reasons.
You integrate the candidate scoring API by claiming an API key and sandbox on sign-up, posting an applicant's signals to one REST endpoint, and reading the JSON score back, with no model training and no rip-and-replace. It drops an AI layer onto your existing stack through the recruitment API for your ATS, no migration required. Most teams calibrate thresholds and go live within one to two weeks, with usage priced per call and no per-seat fees.
Free for Candidate scoring API spec sheet
A one-page reference for the fit-score endpoint: the JSON schema, the three input signals and how to weight them, threshold and confidence fields, and what "explainable" means in the response payload.
Turn CV, assessment, and interview signals into one explainable score, with the breakdown to back every ranking.