
English Skills Assessments
Custom Scorecards
Anti-Fraud Measures
Designed with DEI in Mind


Assess a candidate's English language proficiency in real-time, analyzing accent, vocabulary, fluency, and pronunciation with high accuracy.
Customize scorecards for each interview based on the specific needs of the role. ZenHire allows you to ask job-related questions and measure responses using tailored metrics, ensuring each candidate is assessed on what truly matters.

Our anti-cheating system monitors for unusual behavior like exiting the recording screen, detecting multiple people or voices, and other suspicious activities, ensuring the integrity of every interview.


Exclude sensitive factors and screen fairly. Make data-driven, transparent decisions.
AI interview software screens every applicant in roughly four minutes, scoring communication, logic, soft skills, and CEFR-aligned spoken language so your team only meets people who can actually do the job. The ZenHire AI interview runs 24/7 in any language, with anti-fraud checks and glass-box scoring that excludes demographic attributes.
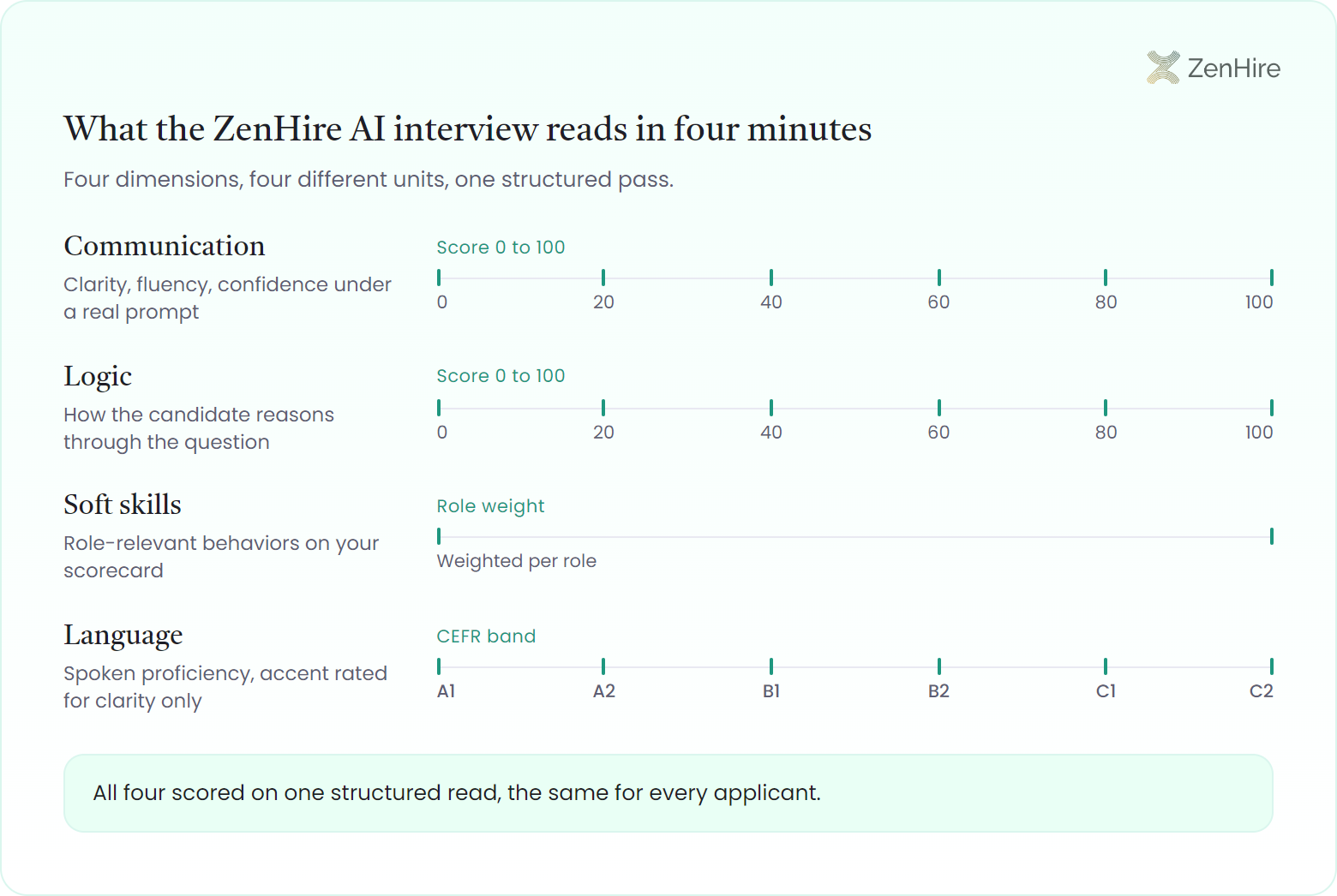
It measures four things at once: how clearly a person communicates, how they reason through a prompt, the soft skills the role needs, and their spoken-language level on the CEFR scale. Every applicant gets the same structured interview read, so a shortlist reflects ability rather than who happened to interview well by phone.
The mechanism is audio-signal analysis plus competency scoring against a scorecard you define. A customer-service role might weight communication and a B2 language floor heavily, drawing on the same interview analysis that scores how a candidate performs the human parts of a job, while a back-office role drops language and leans on logic. One concrete example: two candidates with identical resumes, indistinguishable to CV matching alone, can separate sharply once you see one scored C1 with strong reasoning and the other B1 with scripted answers. The edge case to flag is a role that is almost entirely manual and non-verbal, where a four-minute spoken evaluation tells you less, so you reweight toward the assessments in the test library instead.
On CEFR-aligned spoken language, the same scoring engine aligns 90 to 96 percent with the averaged judgment of five PhD linguists, while untrained recruiters land at just 68 to 75 percent. A four-minute read is not only faster than a phone screen, it is measurably closer to expert ground truth.
| Dimension | What it captures | Scoring |
|---|---|---|
| Communication | Clarity, fluency, confidence under a real prompt | 0 to 100 |
| Logic | How the candidate reasons through the question | 0 to 100 |
| Soft skills | Role-relevant behaviors on your scorecard | Weighted per role |
| Language | Spoken proficiency, accent rated for clarity only | CEFR A1 to C2 |
Around four minutes from start to scored result, versus the 25 to 30 minutes a traditional language screen burns. That short, audio-friendly format also protects candidate experience, holding drop-off down compared with long, video-heavy alternatives.
Here is how the time collapses: the candidate records once, the system transcribes and scores every dimension automatically, and your team opens a ranked shortlist rather than booking live calls. A team that used to phone-screen one applicant at a time can now process thousands per role without slowing down, and the same engine handles high-volume hiring like call center hiring, where a single role can pull thousands of applications. Some argue a four-minute read is too thin to judge a hire, and they are right that it should not be the whole decision. It is not meant to be: the AI interview is a fast, consistent first filter that hands recruiters a ranked shortlist and an explainable scorecard, so human judgment is spent on the few who clear the bar rather than the hundreds who never will. Roles that fill constantly, like call center hiring, see the biggest gains from that first filter.
1. Candidate records
One async take answers your prompts, on audio-only if bandwidth is tight.
2. Auto-transcribe and score
Every dimension is scored in roughly four minutes, no recruiter time spent.
3. Fraud check runs
Scripted, AI-generated, proxy, and multi-speaker signals are flagged on the same pass.
4. Ranked shortlist
Your team reviews a ranked list with explainable scorecards, not raw recordings.
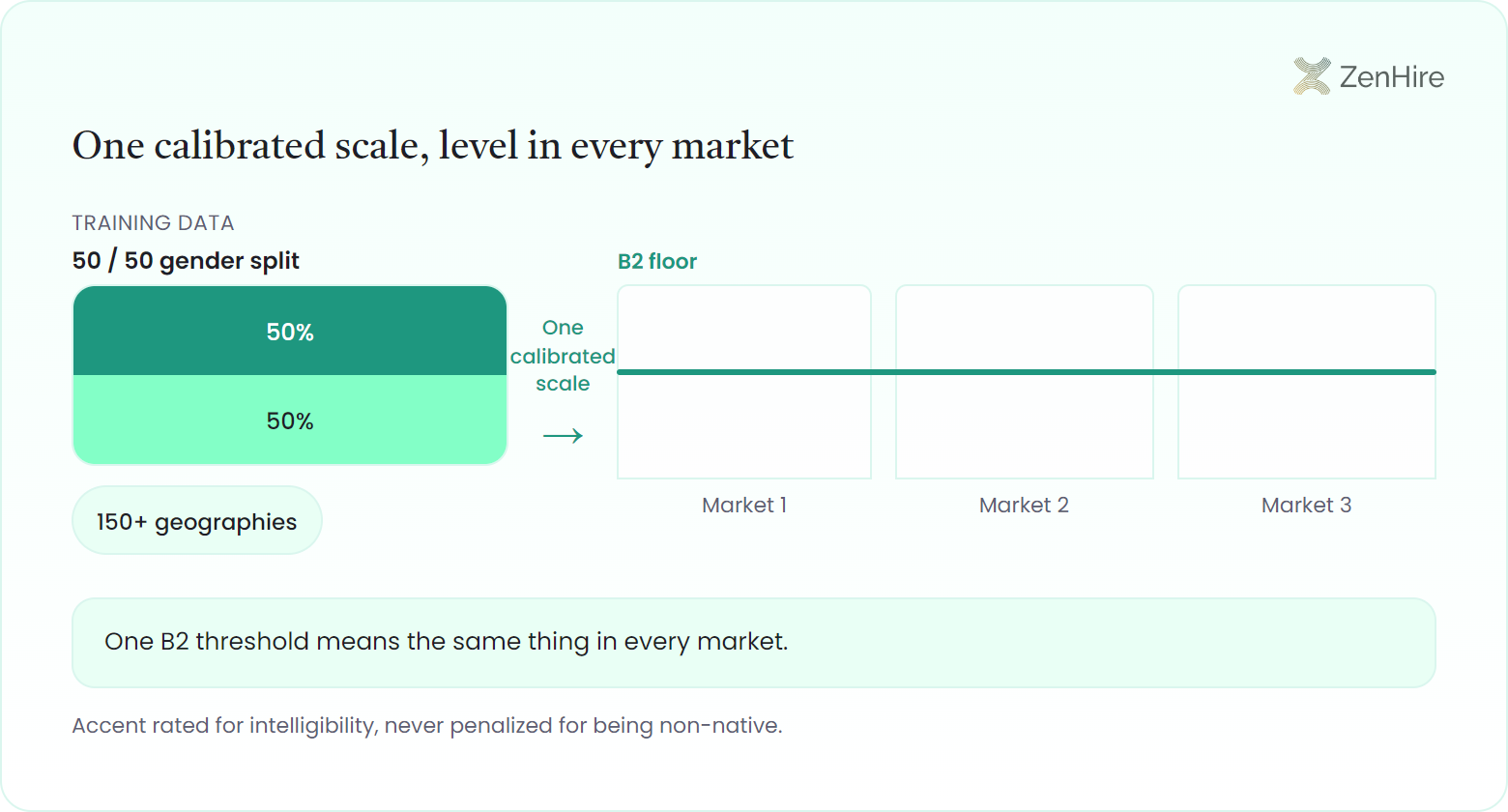
Yes. Candidates complete the screening 24/7 with no scheduling, and spoken-language scoring works across markets and first languages, returning a CEFR level you can set a clear bar against. Accent is rated only for intelligibility and is never penalized for being non-native.
Because it is async and self-serve, an automated video interview platform fills a global pipeline overnight while your recruiters sleep, then ranks everyone by morning. The underlying spoken-language scoring is the same engine exposed in the speech analysis api, so a B2 floor means the same thing everywhere. One concrete example: a role hiring across three time zones gets every applicant scored on the same CEFR scale, instead of varying by whoever ran the phone screen. The edge case worth naming is genuinely low-flow roles with only a handful of applicants, where always-on screening saves less time than it does at volume, though the consistency and the audit trail still hold.
The model was trained on a balanced dataset spanning 150+ geographies with a 50/50 gender split, so a candidate is scored on how clearly they speak, not on where their accent comes from. That is what lets one B2 threshold travel cleanly across every market you hire in.
AI interview software is a tool that records a candidate response once and automatically scores it for communication, logic, soft skills, and spoken language. ZenHire does this in roughly four minutes per candidate and returns an explainable scorecard plus a CEFR level, so every applicant is evaluated on the same structured basis.
The ZenHire AI interview is an automated video interview platform that also supports audio-only screening for low-bandwidth markets. Scoring is built on audio-signal analysis, so candidates on weak connections still get a fair, complete evaluation rather than being filtered out by their hardware.
The ai screening interview tool aligns 90 to 96 percent with PhD linguists on CEFR-aligned spoken language, where untrained recruiters land at 68 to 75 percent. Because scoring is glass-box and deterministic, the same recording yields the same result every run, which a subjective phone screen cannot promise.
Cheating the AI interview is hard to do undetected. Built-in anti-fraud detection flags scripted and AI-generated answers, proxy speakers, and multiple voices with roughly 91 percent detection on each call, and anything suspicious routes to a human review queue instead of silently passing.
The AI interview is built to reduce bias, not add it. Race, gender, ethnicity, and age are architecturally excluded from the inputs and models, every score is explainable and auditable, and the system is SOC 2 Type II certified and GDPR compliant, which can lower exposure compared with undocumented manual screening.
Free for AI interview scoring spec sheet
A one-page reference for the ZenHire AI interview: the four scored dimensions, the CEFR A1 to C2 bands and how to set per-role thresholds, the fraud signals checked on every call, and what is architecturally excluded to keep scoring fair.

Reimagine hiring with ZenHire: AI-powered, ethical, and built for a faster, fairer future.
Book a demo