The ZenHire speech analysis API for hiring scores spoken English from a 4-minute audio or video clip, returning a CEFR A1-C2 level, 0-100 dimensional scores for fluency, vocabulary, and pronunciation, plus built-in fraud signals, from a single REST call.
{
"cefr_level": "B2",
"overall_score": 78,
"dimensions": {
"fluency": 81,
"vocabulary": 74,
"pronunciation": 79,
"accent_intelligibility": 83
},
"fraud_signals": {
"multiple_speakers": false,
"reading_detected": false
}
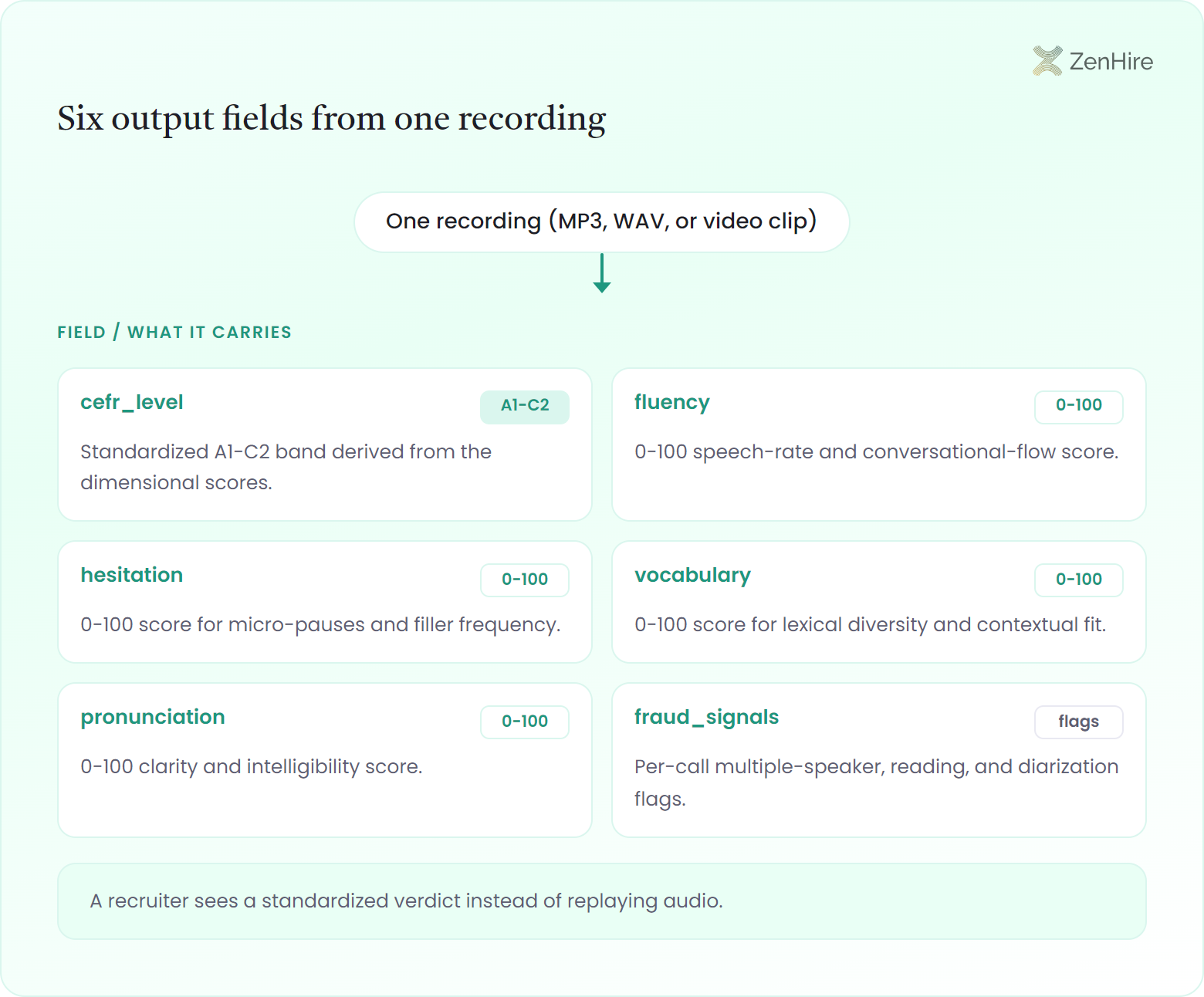
}Each call reads an MP3, WAV, OGG, FLAC, M4A, or AIFF file, or a video clip, and returns one CEFR band from A1 to C2 for the recording plus a CEFR level per dimension, 0-100 sub-scores, an overall number, and fraud signals. A recruiter sees a standardized verdict instead of replaying audio.
The endpoint expects at least 3 minutes of audio to score reliably; where a clip is too short or too noisy to judge, the API returns a low-confidence flag rather than a guessed band, so a thin two-second answer never inflates a score. If only some dimensions can be scored, credits are charged proportionally, and failed runs are never charged. Pair it with an ai interview api and the same recording feeds both the language band and the structured interview score.
The same trained model that powers this endpoint reaches 97% accuracy on CV field extraction and 91% on scripted or AI-generated response detection elsewhere in the ZenHire stack. The speech scores are not a bolt-on, they share one feature-engineered backbone.
| Field | What it carries |
|---|---|
| cefr_level | Standardized A1-C2 band derived from the dimensional scores |
| fluency | 0-100 speech-rate and conversational-flow score |
| hesitation | 0-100 score for micro-pauses and filler frequency |
| vocabulary | 0-100 score for lexical diversity and contextual fit |
| pronunciation | 0-100 clarity and intelligibility score |
| vocabularyCefr, fluencyCefr, accentCefr | A separate CEFR level per dimension alongside the overall band |
| transcript | Full transcript with speaker diarization, a speakerCount, and automatic candidate detection flagged high, medium, or low confidence |
| fraud_signals | Per-call multiple-speaker, reading, and diarization flags |
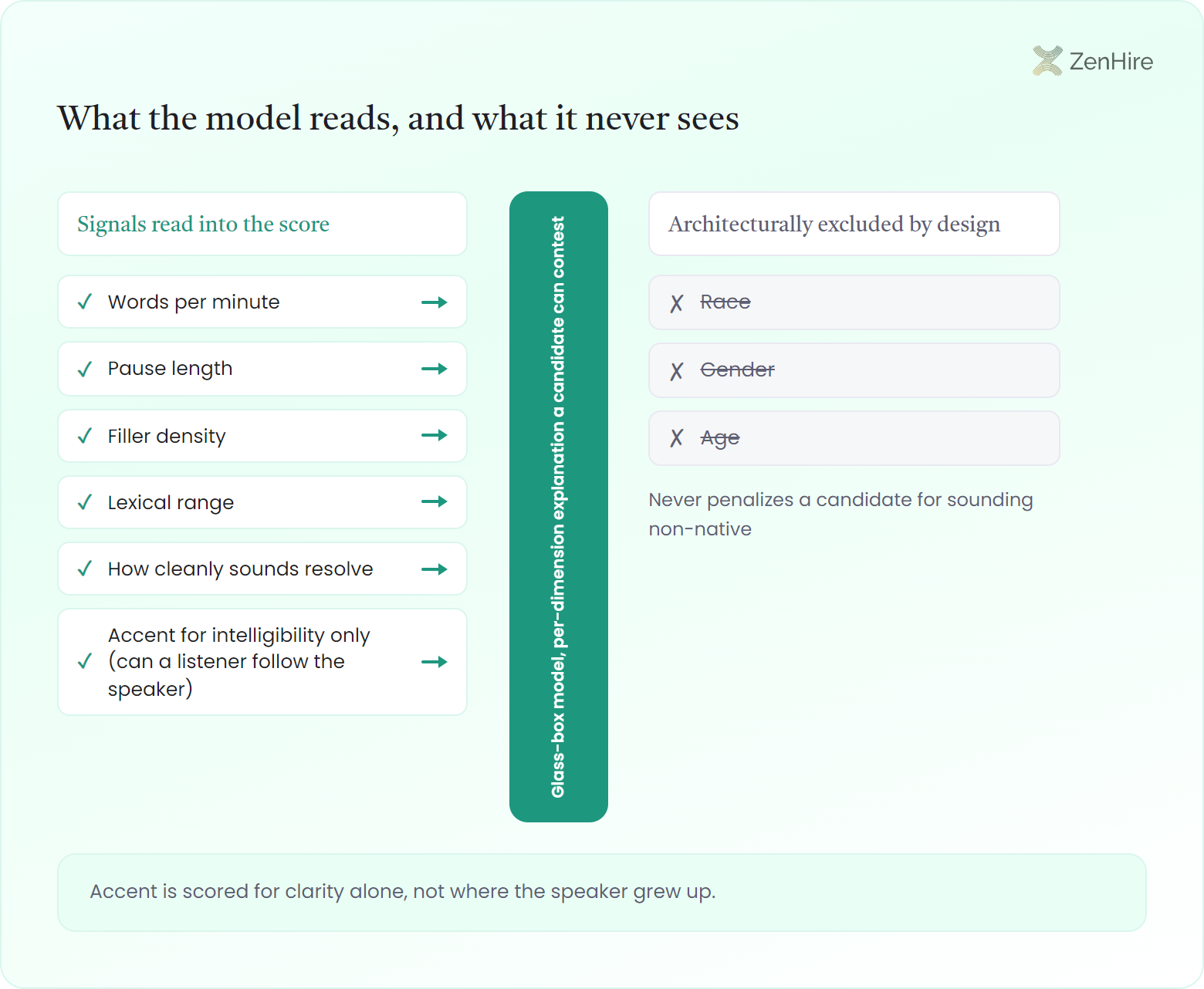
This language scoring api reads acoustic signal: words per minute, pause length, filler density, lexical range, and how cleanly sounds resolve. It is the same read behind ZenHire's interview analysis layer. Accent feeds one axis only, intelligibility, which asks whether a listener can follow the speaker, not where they grew up.
Some buyers fear an automated voice assessment api will quietly mark down regional or non-native accents. It does not: accent is scored for clarity alone, sensitive attributes like race, gender, and age are architecturally excluded from the model by design, and every dimension ships with two plain-language sentences of explanation, written to be safe to surface directly to hiring managers, candidates, and audit reviewers, as part of ZenHire's approach to ethical hiring.
Yes. The same call captures communication signals that map to soft skills, and you can pair it with a soft-skills assessment api and role-weighted scorecards to grade domain answers, since the speech analysis API is context-agnostic across question types. It also scores 16 languages, with a dedicated, most-tuned pipeline for assessing spoken English and a multilingual pipeline covering Spanish, French, German, Hindi, Japanese, Arabic, and more, so one integration covers multilingual hiring programs.
A spoken-language mismatch that slips past screening surfaces on the first live customer call, and by then the cost is sunk: replacing one frontline hire runs $5,000 to $20,000 (industry estimates), with roughly half of frontline leavers gone inside 90 days. Enforcing a hard CEFR floor on the recording itself, before anyone reaches a queue, catches that mismatch for the price of one API call.
1. Send any answer
POST a structured, situational, or open-ended response to /v1/speech-analyze, then poll for the result, typically ready in 2-5 minutes.
2. Read communication signals
Parse fluency, hesitation, and vocabulary as proxies for clarity, confidence, and articulation.
3. Layer a scorecard
Weight domain competencies with the assessments engine for a combined, role-specific verdict.
4. Set the threshold
Require B2 for customer-facing roles or C1 for managerial, then route at scale across your high-volume hiring pipeline.
A speech analysis API for hiring is a REST endpoint that scores a candidate's spoken English from an audio or video clip and returns a CEFR A1-C2 level plus 0-100 dimensional scores as JSON. ZenHire's runs in about 4 minutes per response and adds built-in fraud signals on every call, so a phone screen becomes a single API request: the core need in high-volume bpo hiring.
Scored against a panel of five PhD linguists, the language scoring api lands within their band 90-96% of the time. Hand the same clip to two untrained recruiters and they agree with each other only 68-75% of the time, because ear-fatigue and personal accent bias drift the verdict. The api does not drift: it is a glass-box model, so a re-run returns the identical band and each one arrives with the evidence attached.
The voice assessment api does not penalize non-native accents. Accent is rated for intelligibility only, meaning whether the speaker can be understood, and sensitive attributes like race, gender, and age are architecturally excluded from the inputs and the model.
The speech analysis API runs integrity checks on every call and returns them in a fraud_signals object: multiple-speaker detection catches proxy interviews, reading detection flags scripted or AI-generated answers at 91% accuracy, and diarization isolates the candidate's voice in a two-way conversation for clean scoring.
The speech analysis API accepts MP3, WAV, and other audio formats plus video, which it auto-transcribes. It returns a JSON response with the CEFR level, fluency, vocabulary, pronunciation, and accent-intelligibility scores, an overall number, a fraud_signals object, and optional transcript, candidate-only audio, and per-dimension explanations.
Free for Speech Analysis API quickstart
A developer spec sheet covering the /v1/speech-analyze request and JSON schema, every dimension and the fraud_signals object, sample payloads, and the CEFR thresholds to set for customer-facing and managerial roles.
Drop the speech analysis API into your stack and grade language, soft skills, and integrity from one recording.